Resilient Distributed Dataset (RDDs) are created by starting with a file in the
Hadoop file system (or any other Hadoop-supported file system), or an existing
Scala collection in the driver program, and transforming it.
At a high level,
every Spark application consists of a driver program that runs the user’s main function and executes various parallel
operations on a cluster. The main abstraction Spark provides is a resilient
distributed dataset (RDD), which is a collection of elements
partitioned across the nodes of the cluster that can be operated on in
parallel.
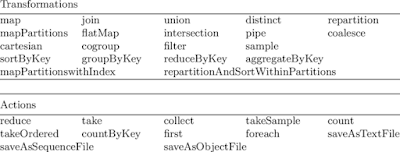
Apache Spark RDD supports two types of Operations-
·
Transformations
·
Actions
a) Parallelize method by which already existing collection can be used in the driver program.
b) By referencing a dataset that is present in an external storage system such as HDFS, HBase, etc.
c) New RDDs can be created from an existing RDD.
Applying transformation built an RDD lineage, also known as RDD operator graph or RDD dependency graph. It is a logical execution plan i.e., it is Directed Acyclic Graph (DAG) of the entire parent RDDs of RDD.
Transformations are
lazy in nature i.e., they get execute when we call an action. They are
not executed immediately. Two most basic type of transformations is a map(),
filter().
After the transformation, the resultant RDD is always different from its parent
RDD. It can be smaller (e.g. filter, count, distinct, sample),
bigger (e.g. flatMap(), union(), Cartesian()) or the same size
(e.g. map).
There are two types of transformations:
·
Narrow
transformation – In Narrow transformation, all the
elements that are required to compute the records in single partition live in
the single partition of parent RDD. A limited subset of partition is used to
calculate the result. Narrow transformations are
the result of map(), filter().
·
Wide
transformation – In wide transformation, all the elements that are required to compute
the records in the single partition may live in many partitions of parent RDD.
The partition may live in many partitions of parent RDD. Wide transformations are the result of groupbyKey() and reducebyKey().
Example of RDD function in Spark Core:
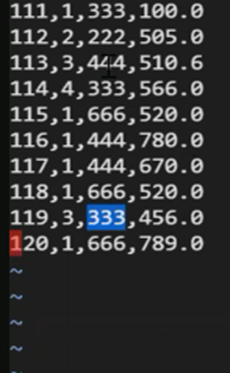
Item Sales Data in file of
4 fields as given below:

Now create file:
Scala> vi item_sales.csv
Insert above data in the file:
Now create RDD to Read the data in Local File System (Text File):
Here
val is immutable variable.
sc is Spark Context.
textFile to read the data.
Home Path is ‘pwd’ in Cloudera.
Item_sales.csv is the file created to store the data.
To check
whether RDD got created or not, give ‘collect()’ command:

To know how many times the Item has been sold, we need to convert the data into Key Value Pairs as per the requirement using a Key which is Item_ID in the case.
To convert each and every item as Key Value Pair, we need to go to MapReduce step.
First, we need to remove the delimiter which is comma (,) in this case
to convert data into key value pair and go for MapReduce (MR) function.


Use Split command wherever
comma (,) syntax is there.
We mention (a(2),1) in above program based on position of Item_Id (0,1,2) in the given data.
Now give print ((foreach(println))the data to check whether converted into Key Value Pair or not:

Use ReduceBy operation to convert data into single output:
x,y are 2 items.

We can also use ‘sortBy’ HOF:
‘sortBy’ is the step where
Reduce will happen.

Based on Shuffle creation, there are 2 kinds of operations:
a)
Narrow
(shuffle won’t happen) à Map,
flatMap & Filter.
b)
Wide
(shuffle happen) à
reduceByKey, GroupByKey, count.

Now Save the file (Write the data) in Local File System (LFS):
Use command ‘saveAsTextFile’ to write the data into LFS.

Why data saved in 2 files only?
Because default partition size
of RDD is 2.
Now save the Data in HDFS:
Now Reduce the size of Partition into single file using Repartition
command:
Now see the Single partition file in LFS (b10_rdd)

Repartition to specific files when data is large:

Repartition will increase or decrease the size of partition which creates shuffling
Now reduce the size of the partition by giving Coalesce:
Coalesce will decrease the size of partition won’t create shuffling.
We go for Repartition process for Skew Data (uneven data distribution).
No comments:
Post a Comment