Spark applications can be deployed and executed using spark-submit in a shell command on a cluster. It can use any of the cluster managers like YARN, Mesos or its own Cluster manager through its uniform interface and there is no extra configuration needed for each one of them separately.
For deploying our Spark application on a cluster, we need to use the spark-submit script of Spark.
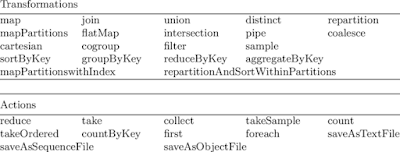
Spark has to do the process:
Spark-submit --class classname mode jar inputfile outputfile location

1.
Submitting Spark application on different
cluster managers like Yarn, Kubernetes, Mesos,
and Stand-alone.
2. Submitting Spark application on client or cluster deployment modes
Spark application needs to be deployed into 3 modes:
a)
Local à Spark itself allocates the Resources (Standalone).
b)
YARN Client à Driver will be running in Edge node. (Dev)
c) YARN Cluster à Driver will be running in any one of the Data Nodes. (Prod)
We need to create Spark environment for IDEs like Eclipse & IntelliJ Idea. After creating the environment, we need to write the code into Executable File (Jar) using Build tool (MAVEN). Finally, take the Jar file and put it into the Cluster.