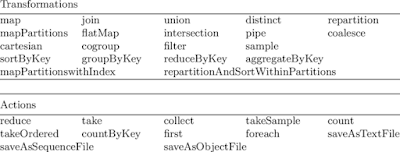
Data
usually comes through raw format in an unorganized manner and processing of
such data is called ‘Information’.
Our
Data are stored in Databases [db] consists set of Tables (Rows & Columns). A Table is an organized collection of data stored in the form
of Rows and Columns. Columns
can be categorized as vertical, while Rows as horizontal. The Columns in a
table are called Fields in records while the Rows can be referred to as unique Records.
For example, a Table that contains Employee data for a company might
contain a row for each employee and columns representing employee information
such as employee number, name, address, job title,
etc.
A Computer can have one or more than one instance of SQL
Server installed. Each instance of SQL Server can contain one or many
databases. Within a database, there are one or many object ownership groups
called schemas. Within each schema there are database objects such as tables,
views, and stored procedures. Some objects such as certificates and asymmetric
keys are contained within the database, but are not contained within a schema.
SQL Server databases are stored in the file
system in files. Files can be grouped into file-groups.
At a minimum, every SQL Server database has two
operating system files: a data file and a log file. Data files contain data and
objects such as tables, indexes, stored procedures, and views. Log files
contain the information that is required to recover all transactions in the
database. Data files can be grouped together in file-groups for allocation and
administration purposes.
The
number of tables in a database is limited only by the number of objects allowed
in a database (2,147,483,647). A standard user-defined table can have up to
1,024 columns. The number of rows in the table is limited only by the storage
capacity of the server.